Client compatibility
Use OpenAI-compatible entry points so existing clients can route through one gateway layer.
Run a self-hosted gateway between OpenAI-compatible clients and multiple upstream model providers, with local routing policy, fallback, telemetry, config publishing, diagnostics, updates, and rollback.
If this gateway fits your self-hosted LLM infrastructure workflow, star the repository after evaluation.
Why use it
AI Model Gateway is built for teams that want to keep provider keys, routing policy, request telemetry, and incident workflows inside their own environment instead of delegating the control plane to a hosted broker.
Use OpenAI-compatible entry points so existing clients can route through one gateway layer.
Route around upstream quota, timeout, and failure signals without moving keys or policies out of your environment.
Keep ingress and provider-facing limits visible alongside model routing, telemetry, and operator workflows.
Preview, diff, publish, audit, and roll back config changes instead of editing a live proxy file.
Operational proof
The demo starts two fake OpenAI-compatible upstreams. The primary provider returns 429, the gateway serves the request through the fallback provider, rewrites the forwarded model, and records route_mode=model_fallback.
go test ./examples/provider-fallback -run TestProviderFallbackDemo -v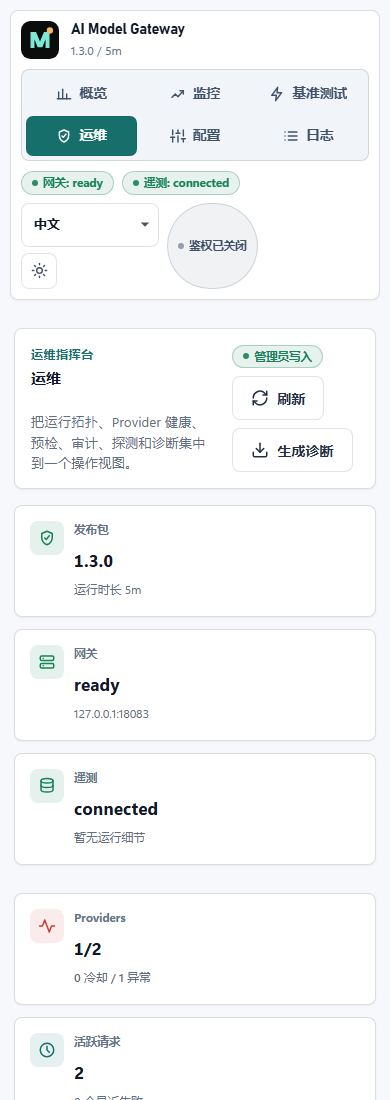
Fit check
Review evidence
Try the packaged v1.4.4 runtime with checksum verification, local config, runtime directories, and supervised startup commands.
Open release install pathReview CI gates, local reproduction commands, runtime smoke checks, feature proof points, and current capability boundaries.
Open quality evidenceInspect admin auth, same-origin browser writes, provider-key handling, SSRF defenses, telemetry sensitivity, and update trust.
Open security modelNext step
Start with the short evaluation path or provider fallback demo. If the project matches your self-hosted LLM gateway needs, starring the repository helps other operators find it.