Provider fallback
Route around quota, timeout, and upstream failures while keeping provider keys and policy local.
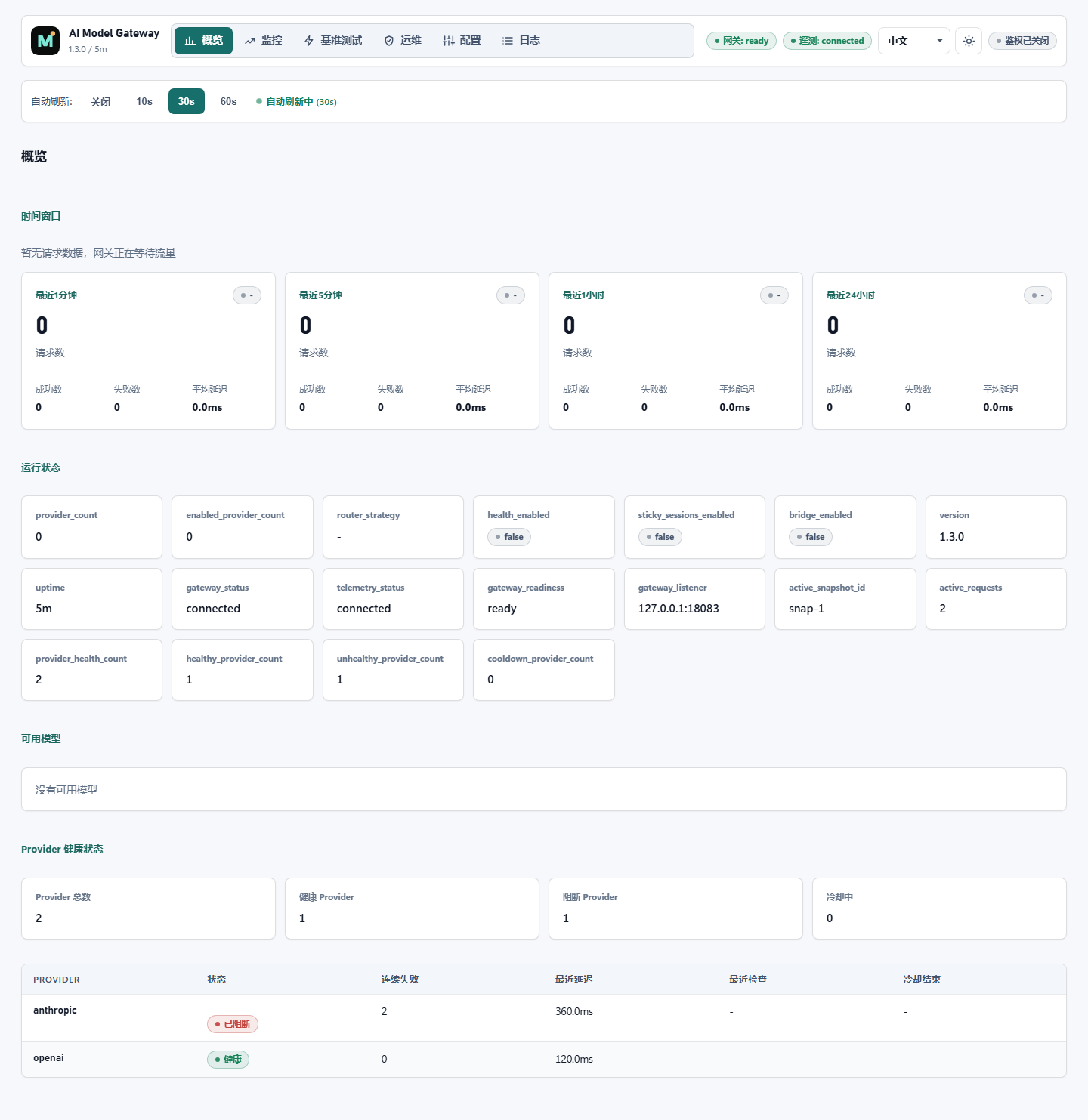
Self-hosted LLM operations gateway for teams that want routing, fallback, telemetry, benchmarks, config publishing, diagnostics, updates, and rollback inside their own environment.
If this matches your self-hosted LLM infrastructure needs, star the repository so more operators can find it.
Built for operators
Route around quota, timeout, and upstream failures while keeping provider keys and policy local.
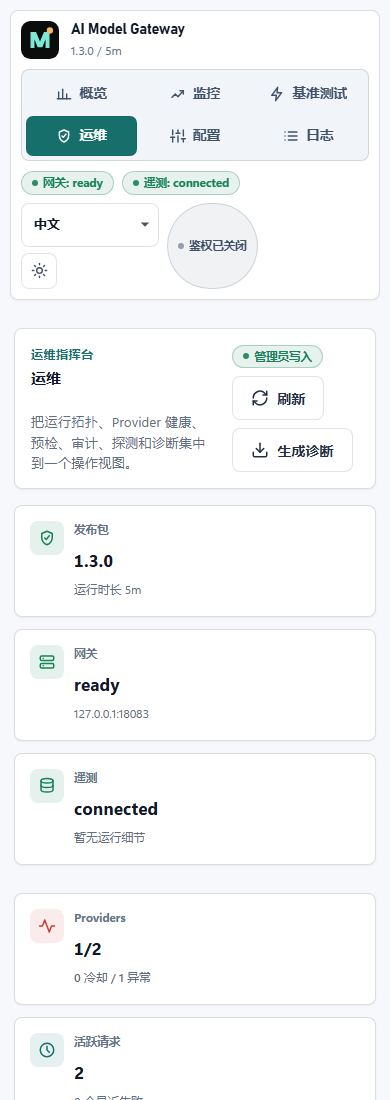
Preview, diff, publish, audit, and roll back routing changes instead of editing a live proxy file.
Inspect traffic, latency, model usage, provider health, request logs, and cost signals in one place.
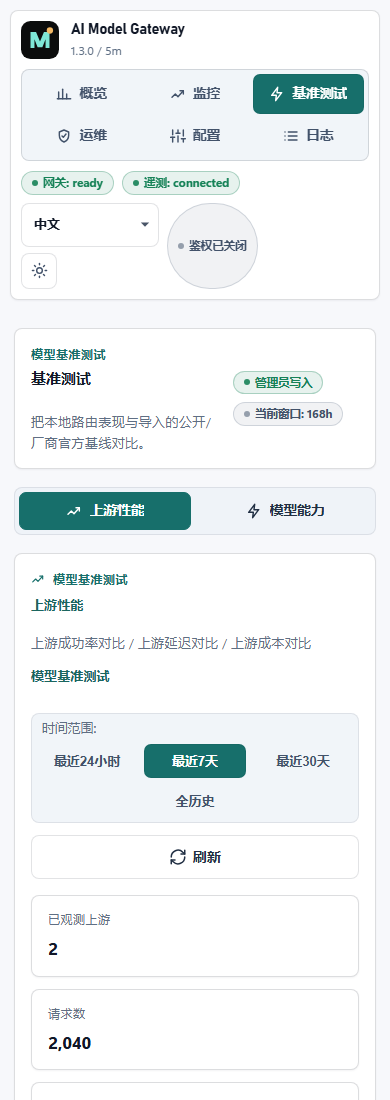
Compare models with exact, judge, JSON, tool, and stream scoring before promoting traffic.
Executable proof
The provider fallback demo starts two fake OpenAI-compatible upstreams. The primary returns 429, the gateway serves the fallback provider, rewrites the forwarded model, and records route_mode=model_fallback.
go test ./examples/provider-fallback -run TestProviderFallbackDemo -v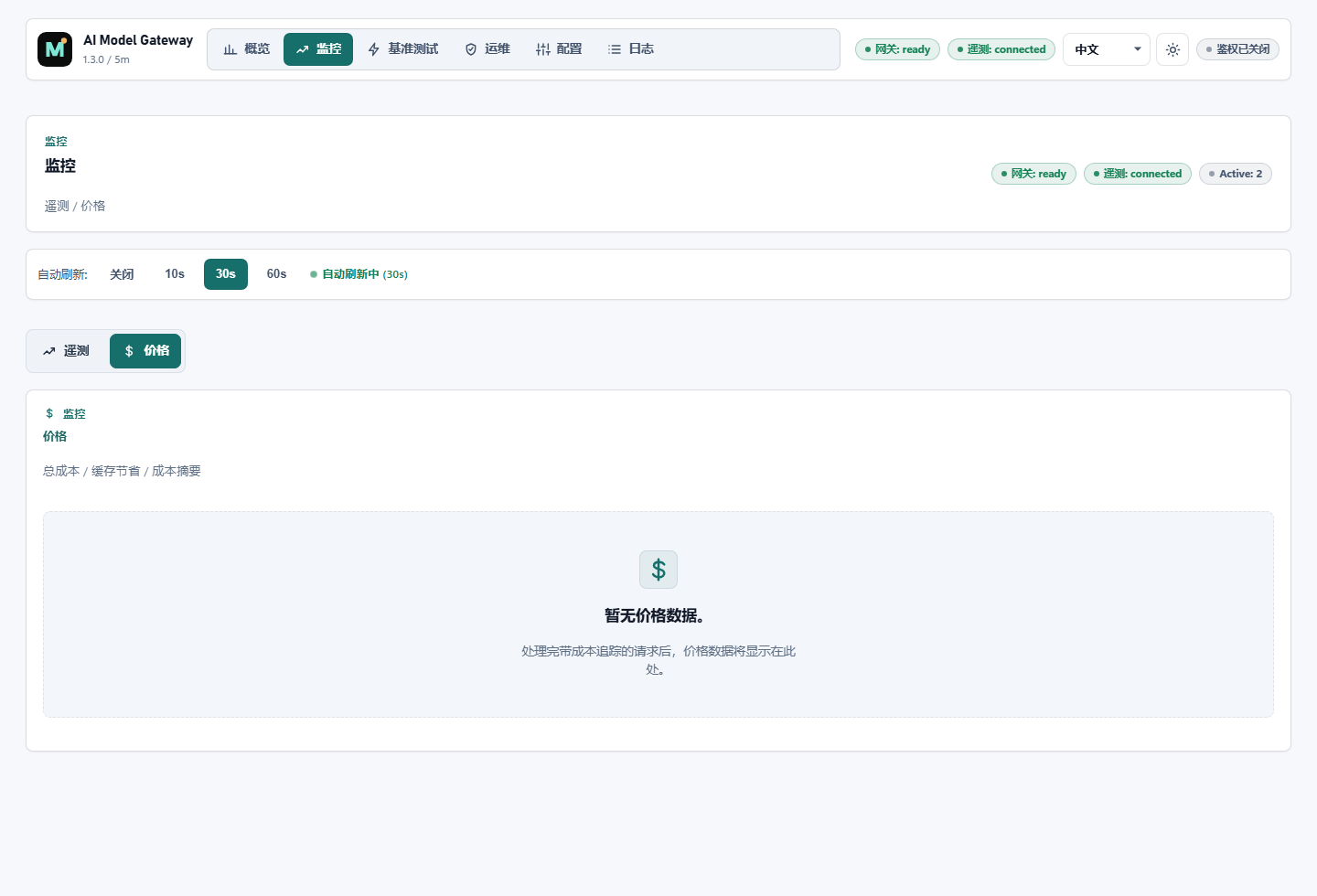
Review evidence
Try the packaged v1.4.4 runtime with checksum verification, local config, runtime directories, and supervised startup commands.
Open release install pathReview CI gates, local reproduction commands, runtime smoke checks, feature proof points, and current capability boundaries.
Open quality evidenceInspect admin auth, same-origin browser writes, provider-key handling, SSRF defenses, telemetry sensitivity, and update trust.
Open security modelEvaluation path
Support discovery
If AI Model Gateway fits your self-hosted routing, fallback, telemetry, or config rollback workflow, star the repository after evaluation. Feedback is also useful if something blocks adoption.